![]()
01. PyTorch Workflow Exercise Template
The following is a template for the PyTorch workflow exercises.
It’s only starter code and it’s your job to fill in the blanks.
Because of the flexibility of PyTorch, there may be more than one way to answer the question.
Don’t worry about trying to be right just try writing code that suffices the question.
You can see one form of solutions on GitHub (but try the exercises below yourself first!).
# Import necessary libraries
import torch
from torch import nn
from matplotlib import pyplot as plt
torch.__version__
'2.5.1+cu121'
# Setup device-agnostic code
if torch.cuda.is_available():
device = "cuda"
else: device = "cpu"
device
'cuda'
1. Create a straight line dataset using the linear regression formula (weight * X + bias).
- Set
weight=0.3andbias=0.9there should be at least 100 datapoints total. - Split the data into 80% training, 20% testing.
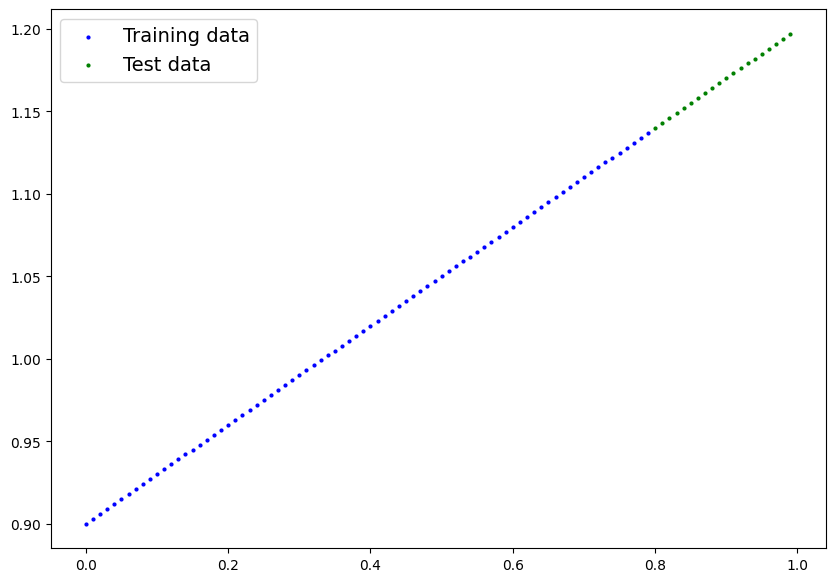
- Plot the training and testing data so it becomes visual.
Your output of the below cell should look something like:
Number of X samples: 100
Number of y samples: 100
First 10 X & y samples:
X: tensor([0.0000, 0.0100, 0.0200, 0.0300, 0.0400, 0.0500, 0.0600, 0.0700, 0.0800,
0.0900])
y: tensor([0.9000, 0.9030, 0.9060, 0.9090, 0.9120, 0.9150, 0.9180, 0.9210, 0.9240,
0.9270])
Of course the numbers in X and y may be different but ideally they’re created using the linear regression formula.
# Create the data parameters
weight = 0.3
bias = 0.9
start = 0
end = 1
step = 0.01
# Make X and y using linear regression feature
X = torch.arange(start, end, step).unsqueeze(dim=1)
y = weight * X + bias
print(f"Number of X samples: {len(X)}")
print(f"Number of y samples: {len(y)}")
print(f"First 10 X & y samples:\nX: {X[:10]}\ny: {y[:10]}")
Number of X samples: 100
Number of y samples: 100
First 10 X & y samples:
X: tensor([[0.0000],
[0.0100],
[0.0200],
[0.0300],
[0.0400],
[0.0500],
[0.0600],
[0.0700],
[0.0800],
[0.0900]])
y: tensor([[0.9000],
[0.9030],
[0.9060],
[0.9090],
[0.9120],
[0.9150],
[0.9180],
[0.9210],
[0.9240],
[0.9270]])
# Split the data into training and testing
split = int(len(X) * 0.8)
X_train = X[:split]
y_train = y[:split]
X_test = X[split:]
y_test = y[split:]
len(X_train), len(X_test)
(80, 20)
# Plot the training and testing data
def plot_predictions(train_data = X_train,
train_labels = y_train,
test_data = X_test,
test_labels = y_test,
predictions = None):
plt.figure(figsize=(10,7))
plt.scatter(train_data, train_labels, c="b", s=4, label="Training data")
plt.scatter(test_data, test_labels, c="g", s=4, label="Test data")
if predictions is not None:
plt.scatter(test_data, predictions, c="r", s=4, label="Predictions")
plt.legend(prop={"size": 14});
plot_predictions()
2. Build a PyTorch model by subclassing nn.Module.
- Inside should be a randomly initialized
nn.Parameter()withrequires_grad=True, one forweightsand one forbias. - Implement the
forward()method to compute the linear regression function you used to create the dataset in 1. - Once you’ve constructed the model, make an instance of it and check its
state_dict(). - Note: If you’d like to use
nn.Linear()instead ofnn.Parameter()you can.
# Create PyTorch linear regression model by subclassing nn.Module
class LinearRegressionModelV3(nn.Module):
def __init__(self):
super().__init__()
self.linear_layer = nn.Linear(in_features=1, out_features=1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.linear_layer(x)
# Instantiate the model and put it to the target device
torch.manual_seed(42)
model_3 = LinearRegressionModelV3()
model_3, model_3.state_dict()
(LinearRegressionModelV3(
(linear_layer): Linear(in_features=1, out_features=1, bias=True)
),
OrderedDict([('linear_layer.weight', tensor([[0.7645]])),
('linear_layer.bias', tensor([0.8300]))]))
# Put model on target device
model_3.to(device)
next(model_3.parameters()).device
device(type='cuda', index=0)
3. Create a loss function and optimizer using nn.L1Loss() and torch.optim.SGD(params, lr) respectively.
- Set the learning rate of the optimizer to be 0.01 and the parameters to optimize should be the model parameters from the model you created in 2.
- Write a training loop to perform the appropriate training steps for 300 epochs.
- The training loop should test the model on the test dataset every 20 epochs.
# Create the loss function and optimizer
loss_fn = nn.L1Loss()
optimizer = torch.optim.SGD(params=model_3.parameters(),
lr=0.01)
# Training loop
torch.manual_seed(42)
# Train model for 300 epochs
epochs = 300
# Send data to target device
train_X = X_train.to(device)
train_y = y_train.to(device)
test_X = X_test.to(device)
test_y = y_test.to(device)
for epoch in range(epochs):
### Training
# Put model in train mode
model_3.train()
# 1. Forward pass
pred_y = model_3(train_X)
# 2. Calculate loss
loss = loss_fn(pred_y, train_y)
# 3. Zero gradients
optimizer.zero_grad()
# 4. Backpropagation
loss.backward()
# 5. Step the optimizer
optimizer.step()
### Perform testing every 20 epochs
if epoch % 20 == 0:
# Put model in evaluation mode and setup inference context
model_3.eval()
with torch.inference_mode():
# 1. Forward pass
pred_test = model_3(test_X)
# 2. Calculate test loss
test_loss = loss_fn(pred_test, test_y)
# Print out what's happening
print(f"Epoch: {epoch} | Train loss: {loss:.3f} | Test loss: {test_loss:.3f}")
Epoch: 0 | Train loss: 0.128 | Test loss: 0.337
Epoch: 20 | Train loss: 0.082 | Test loss: 0.218
Epoch: 40 | Train loss: 0.072 | Test loss: 0.175
Epoch: 60 | Train loss: 0.065 | Test loss: 0.153
Epoch: 80 | Train loss: 0.058 | Test loss: 0.137
Epoch: 100 | Train loss: 0.051 | Test loss: 0.121
Epoch: 120 | Train loss: 0.045 | Test loss: 0.104
Epoch: 140 | Train loss: 0.038 | Test loss: 0.088
Epoch: 160 | Train loss: 0.031 | Test loss: 0.072
Epoch: 180 | Train loss: 0.024 | Test loss: 0.056
Epoch: 200 | Train loss: 0.017 | Test loss: 0.040
Epoch: 220 | Train loss: 0.010 | Test loss: 0.024
Epoch: 240 | Train loss: 0.003 | Test loss: 0.007
Epoch: 260 | Train loss: 0.008 | Test loss: 0.007
Epoch: 280 | Train loss: 0.008 | Test loss: 0.007
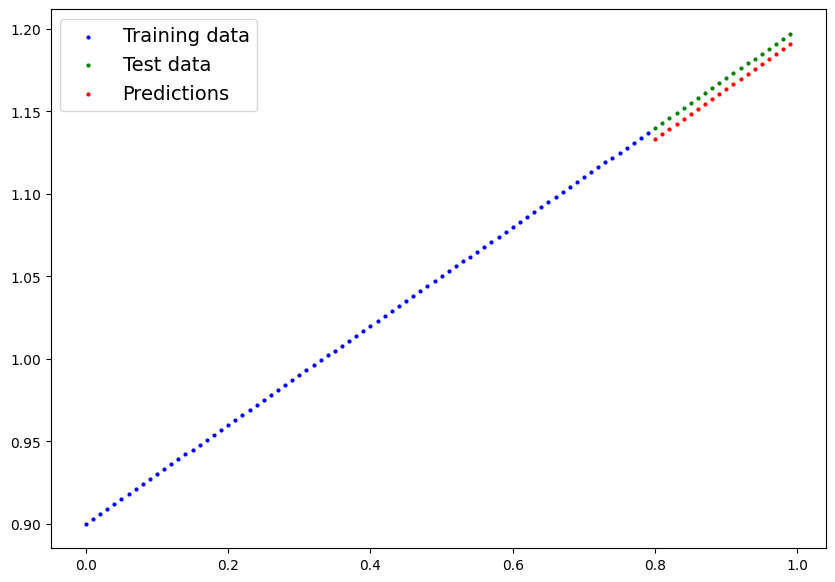
4. Make predictions with the trained model on the test data.
- Visualize these predictions against the original training and testing data (note: you may need to make sure the predictions are not on the GPU if you want to use non-CUDA-enabled libraries such as matplotlib to plot).
# Make predictions with the model
model_3.eval()
with torch.inference_mode():
preds_y = model_3(test_X)
preds_y
tensor([[1.1333],
[1.1363],
[1.1393],
[1.1423],
[1.1454],
[1.1484],
[1.1514],
[1.1545],
[1.1575],
[1.1605],
[1.1635],
[1.1666],
[1.1696],
[1.1726],
[1.1757],
[1.1787],
[1.1817],
[1.1847],
[1.1878],
[1.1908]], device='cuda:0')
# Plot the predictions (these may need to be on a specific device)
plot_predictions(predictions=preds_y.cpu())
5. Save your trained model’s state_dict() to file.
- Create a new instance of your model class you made in 2. and load in the
state_dict()you just saved to it. - Perform predictions on your test data with the loaded model and confirm they match the original model predictions from 4.
from pathlib import Path
# 1. Create models directory
MODEL_PATH = Path("models")
MODEL_PATH.mkdir(parents=True, exist_ok=True)
# 2. Create model save path
MODEL_NAME = "01_pytorch_workflow_model_3"
MODEL_SAVE_PATH = MODEL_PATH / MODEL_NAME
# 3. Save the model state dict
print(f"Saving model to: {MODEL_SAVE_PATH}")
torch.save(obj=model_3.state_dict(),
f=MODEL_SAVE_PATH)
Saving model to: models/01_pytorch_workflow_model_3
# Create new instance of model and load saved state dict (make sure to put it on the target device)
loaded_model_3 = LinearRegressionModelV3()
loaded_model_3.load_state_dict(torch.load(MODEL_SAVE_PATH))
loaded_model_3.to(device)
next(loaded_model_3.parameters()).device
<ipython-input-15-da410fc80d33>:3: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
loaded_model_3.load_state_dict(torch.load(MODEL_SAVE_PATH))
device(type='cuda', index=0)
# Make predictions with loaded model and compare them to the previous
loaded_model_3.eval()
with torch.inference_mode():
loaded_model_3_preds = loaded_model_3(test_X)
preds_y == loaded_model_3_preds
tensor([[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True],
[True]], device='cuda:0')