![]()
02. PyTorch Classification Exercises
The following is a template for 02. PyTorch Classification exercises.
It’s only starter code and it’s your job to fill in the blanks.
Because of the flexibility of PyTorch, there may be more than one way to answer the question.
Don’t worry about trying to be right just try writing code that suffices the question.
Resources
- These exercises are based on notebook 02 of the learn PyTorch course.
- You can see one form of solutions on GitHub (but try the exercises below yourself first!).
# Import torch
import torch
from torch import nn
# Setup device agnostic code
device = "cuda" if torch.cuda.is_available() else "cpu"
print(device)
# Setup random seed
RANDOM_SEED = 42
cuda
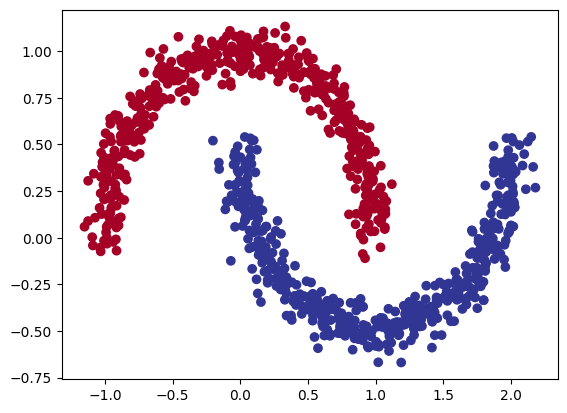
1. Make a binary classification dataset with Scikit-Learn’s make_moons() function.
- For consistency, the dataset should have 1000 samples and a
random_state=42. - Turn the data into PyTorch tensors.
- Split the data into training and test sets using
train_test_splitwith 80% training and 20% testing.
# Create a dataset with Scikit-Learn's make_moons()
from sklearn.datasets import make_moons
# set number of samples
n_samples = 1000
# Create moon dataset
X, y = make_moons(n_samples,
noise=0.07,
random_state=RANDOM_SEED)
len(X), len(y)
(1000, 1000)
print(f"First 5 samples of X:\n {X[:5]}")
print(f"First 5 samples of y:\n {y[:5]}")
First 5 samples of X:
[[-0.03341062 0.4213911 ]
[ 0.99882703 -0.4428903 ]
[ 0.88959204 -0.32784256]
[ 0.34195829 -0.41768975]
[-0.83853099 0.53237483]]
First 5 samples of y:
[1 1 1 1 0]
# Turn data into a DataFrame
import pandas as pd
moons = pd.DataFrame({"X1": X[:, 0],
"X2": X[:, 1],
"label": y})
moons.head()
| X1 | X2 | label | |
|---|---|---|---|
| 0 | -0.033411 | 0.421391 | 1 |
| 1 | 0.998827 | -0.442890 | 1 |
| 2 | 0.889592 | -0.327843 | 1 |
| 3 | 0.341958 | -0.417690 | 1 |
| 4 | -0.838531 | 0.532375 | 0 |
# Visualize the data on a scatter plot
import matplotlib.pyplot as plt
plt.scatter(x=X[:, 0],
y=X[:, 1],
c=y,
cmap=plt.cm.RdYlBu);
# Turn data into tensors of dtype float
X = torch.from_numpy(X).type(torch.float)
y = torch.from_numpy(y).type(torch.float)
# Split the data into train and test sets (80% train, 20% test)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
test_size=0.20,
random_state=RANDOM_SEED)
len(X_train), len(X_test), len(y_train), len(y_test)
(800, 200, 800, 200)
2. Build a model by subclassing nn.Module that incorporates non-linear activation functions and is capable of fitting the data you created in 1.
- Feel free to use any combination of PyTorch layers (linear and non-linear) you want.
import torch
from torch import nn
# Inherit from nn.Module to make a model capable of fitting the mooon data
class MoonModelV0(nn.Module):
def __init__(self):
super().__init__()
self.layer1 = nn.Linear(in_features=2, out_features=10)
self.layer2 = nn.Linear(in_features=10, out_features=10)
self.layer3 = nn.Linear(in_features=10, out_features=1)
self.relu = nn.ReLU()
def forward(self, x):
return self.layer3(self.relu(self.layer2(self.relu(self.layer1(x)))))
# Instantiate the model
model_1 = MoonModelV0().to(device)
model_1
MoonModelV0(
(layer1): Linear(in_features=2, out_features=10, bias=True)
(layer2): Linear(in_features=10, out_features=10, bias=True)
(layer3): Linear(in_features=10, out_features=1, bias=True)
(relu): ReLU()
)
3. Setup a binary classification compatible loss function and optimizer to use when training the model built in 2.
# Setup loss function
loss_fn = nn.BCEWithLogitsLoss()
# Setup optimizer to optimize model's parameters
optimizer = torch.optim.SGD(params=model_1.parameters(),
lr=0.2)
4. Create a training and testing loop to fit the model you created in 2 to the data you created in 1.
- Do a forward pass of the model to see what’s coming out in the form of logits, prediction probabilities and labels.
- To measure model accuray, you can create your own accuracy function or use the accuracy function in TorchMetrics.
- Train the model for long enough for it to reach over 96% accuracy.
- The training loop should output progress every 10 epochs of the model’s training and test set loss and accuracy.
# What's coming out of our model?
# logits (raw outputs of model)
print("Logits:")
print(model_1(X_train.to(device)[:10]).squeeze())
# Prediction probabilities
print("Pred probs:")
print(torch.sigmoid(model_1(X_train.to(device)[:10]).squeeze()))
# Prediction labels
print("Pred labels:")
print(torch.round(torch.sigmoid(model_1(X_train.to(device)[:10]).squeeze())))
Logits:
tensor([-0.3213, -0.2489, -0.3208, -0.3197, -0.2796, -0.3042, -0.2852, -0.2762,
-0.3351, -0.2504], device='cuda:0', grad_fn=<SqueezeBackward0>)
Pred probs:
tensor([0.4204, 0.4381, 0.4205, 0.4208, 0.4305, 0.4245, 0.4292, 0.4314, 0.4170,
0.4377], device='cuda:0', grad_fn=<SigmoidBackward0>)
Pred labels:
tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], device='cuda:0',
grad_fn=<RoundBackward0>)
# Let's calculuate the accuracy using accuracy from TorchMetrics
!pip -q install torchmetrics # Colab doesn't come with torchmetrics
from torchmetrics import Accuracy
acc_fn = Accuracy(task="binary", num_classes=2).to(device)
## TODO: Uncomment this code to use the Accuracy function
# acc_fn = Accuracy(task="multiclass", num_classes=2).to(device) # send accuracy function to device
# acc_fn
## TODO: Uncomment this to set the seed
torch.manual_seed(RANDOM_SEED)
# Setup epochs
epochs = 800
# Send data to the device
X_train, y_train = X_train.to(device), y_train.to(device)
X_test, y_test = X_test.to(device), y_test.to(device)
# Loop through the data
for epoch in range(epochs):
### Training
model_1.train()
# 1. Forward pass (logits output)
y_logits = model_1(X_train).squeeze()
# Turn logits into prediction probabilities
y_pred_probs = torch.sigmoid(y_logits)
# Turn prediction probabilities into prediction labels
y_pred = torch.round(y_pred_probs)
# 2. Calculaute the loss
loss = loss_fn(y_logits, y_train) # loss = compare model raw outputs to desired model outputs
# Calculate the accuracy
acc = acc_fn(y_pred, y_train.int()) # the accuracy function needs to compare pred labels (not logits) with actual labels
# 3. Zero the gradients
optimizer.zero_grad()
# 4. Loss backward (perform backpropagation) - https://brilliant.org/wiki/backpropagation/#:~:text=Backpropagation%2C%20short%20for%20%22backward%20propagation,to%20the%20neural%20network's%20weights.
loss.backward()
# 5. Step the optimizer (gradient descent) - https://towardsdatascience.com/gradient-descent-algorithm-a-deep-dive-cf04e8115f21#:~:text=Gradient%20descent%20(GD)%20is%20an,e.g.%20in%20a%20linear%20regression)
optimizer.step()
### Testing
model_1.eval()
with torch.inference_mode():
# 1. Forward pass (to get the logits)
test_logits = model_1(X_test).squeeze()
# Turn the test logits into prediction labels
test_pred_probs = torch.sigmoid(test_logits)
test_pred = torch.round(test_pred_probs)
# 2. Caculate the test loss/acc
test_loss = loss_fn(test_logits, y_test)
test_acc = acc_fn(test_pred, y_test.int())
# Print out what's happening every 10 epochs
if epoch % 10 == 0:
print(f"Epoch: {epoch} | Loss: {loss:.4f}, Acc: {acc:.2f}% | Test loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%")
Epoch: 0 | Loss: 0.7046, Acc: 0.50% | Test loss: 0.7010, Test Acc: 0.50%
Epoch: 10 | Loss: 0.6858, Acc: 0.50% | Test loss: 0.6836, Test Acc: 0.50%
Epoch: 20 | Loss: 0.6689, Acc: 0.75% | Test loss: 0.6674, Test Acc: 0.75%
Epoch: 30 | Loss: 0.6441, Acc: 0.77% | Test loss: 0.6426, Test Acc: 0.77%
Epoch: 40 | Loss: 0.6006, Acc: 0.78% | Test loss: 0.5991, Test Acc: 0.75%
Epoch: 50 | Loss: 0.5324, Acc: 0.79% | Test loss: 0.5323, Test Acc: 0.75%
Epoch: 60 | Loss: 0.4536, Acc: 0.81% | Test loss: 0.4560, Test Acc: 0.76%
Epoch: 70 | Loss: 0.3841, Acc: 0.83% | Test loss: 0.3879, Test Acc: 0.78%
Epoch: 80 | Loss: 0.3304, Acc: 0.85% | Test loss: 0.3333, Test Acc: 0.82%
Epoch: 90 | Loss: 0.2892, Acc: 0.87% | Test loss: 0.2898, Test Acc: 0.86%
Epoch: 100 | Loss: 0.2559, Acc: 0.88% | Test loss: 0.2547, Test Acc: 0.88%
Epoch: 110 | Loss: 0.2331, Acc: 0.89% | Test loss: 0.2300, Test Acc: 0.92%
Epoch: 120 | Loss: 0.2178, Acc: 0.90% | Test loss: 0.2129, Test Acc: 0.92%
Epoch: 130 | Loss: 0.2064, Acc: 0.91% | Test loss: 0.2002, Test Acc: 0.93%
Epoch: 140 | Loss: 0.1970, Acc: 0.92% | Test loss: 0.1901, Test Acc: 0.93%
Epoch: 150 | Loss: 0.1885, Acc: 0.92% | Test loss: 0.1810, Test Acc: 0.93%
Epoch: 160 | Loss: 0.1801, Acc: 0.92% | Test loss: 0.1724, Test Acc: 0.93%
Epoch: 170 | Loss: 0.1718, Acc: 0.93% | Test loss: 0.1638, Test Acc: 0.93%
Epoch: 180 | Loss: 0.1633, Acc: 0.93% | Test loss: 0.1551, Test Acc: 0.93%
Epoch: 190 | Loss: 0.1545, Acc: 0.94% | Test loss: 0.1462, Test Acc: 0.93%
Epoch: 200 | Loss: 0.1454, Acc: 0.94% | Test loss: 0.1370, Test Acc: 0.94%
Epoch: 210 | Loss: 0.1362, Acc: 0.94% | Test loss: 0.1278, Test Acc: 0.95%
Epoch: 220 | Loss: 0.1269, Acc: 0.95% | Test loss: 0.1185, Test Acc: 0.96%
Epoch: 230 | Loss: 0.1176, Acc: 0.95% | Test loss: 0.1094, Test Acc: 0.96%
Epoch: 240 | Loss: 0.1084, Acc: 0.96% | Test loss: 0.1005, Test Acc: 0.98%
Epoch: 250 | Loss: 0.0994, Acc: 0.97% | Test loss: 0.0921, Test Acc: 0.98%
Epoch: 260 | Loss: 0.0908, Acc: 0.97% | Test loss: 0.0838, Test Acc: 0.98%
Epoch: 270 | Loss: 0.0828, Acc: 0.98% | Test loss: 0.0760, Test Acc: 0.98%
Epoch: 280 | Loss: 0.0754, Acc: 0.98% | Test loss: 0.0689, Test Acc: 0.99%
Epoch: 290 | Loss: 0.0686, Acc: 0.99% | Test loss: 0.0625, Test Acc: 0.99%
Epoch: 300 | Loss: 0.0626, Acc: 0.99% | Test loss: 0.0566, Test Acc: 1.00%
Epoch: 310 | Loss: 0.0571, Acc: 0.99% | Test loss: 0.0515, Test Acc: 1.00%
Epoch: 320 | Loss: 0.0523, Acc: 0.99% | Test loss: 0.0470, Test Acc: 1.00%
Epoch: 330 | Loss: 0.0480, Acc: 0.99% | Test loss: 0.0430, Test Acc: 1.00%
Epoch: 340 | Loss: 0.0441, Acc: 0.99% | Test loss: 0.0394, Test Acc: 1.00%
Epoch: 350 | Loss: 0.0407, Acc: 1.00% | Test loss: 0.0362, Test Acc: 1.00%
Epoch: 360 | Loss: 0.0377, Acc: 1.00% | Test loss: 0.0334, Test Acc: 1.00%
Epoch: 370 | Loss: 0.0350, Acc: 1.00% | Test loss: 0.0308, Test Acc: 1.00%
Epoch: 380 | Loss: 0.0327, Acc: 1.00% | Test loss: 0.0286, Test Acc: 1.00%
Epoch: 390 | Loss: 0.0305, Acc: 1.00% | Test loss: 0.0266, Test Acc: 1.00%
Epoch: 400 | Loss: 0.0286, Acc: 1.00% | Test loss: 0.0248, Test Acc: 1.00%
Epoch: 410 | Loss: 0.0269, Acc: 1.00% | Test loss: 0.0232, Test Acc: 1.00%
Epoch: 420 | Loss: 0.0254, Acc: 1.00% | Test loss: 0.0218, Test Acc: 1.00%
Epoch: 430 | Loss: 0.0240, Acc: 1.00% | Test loss: 0.0205, Test Acc: 1.00%
Epoch: 440 | Loss: 0.0227, Acc: 1.00% | Test loss: 0.0194, Test Acc: 1.00%
Epoch: 450 | Loss: 0.0215, Acc: 1.00% | Test loss: 0.0183, Test Acc: 1.00%
Epoch: 460 | Loss: 0.0205, Acc: 1.00% | Test loss: 0.0174, Test Acc: 1.00%
Epoch: 470 | Loss: 0.0195, Acc: 1.00% | Test loss: 0.0165, Test Acc: 1.00%
Epoch: 480 | Loss: 0.0186, Acc: 1.00% | Test loss: 0.0157, Test Acc: 1.00%
Epoch: 490 | Loss: 0.0178, Acc: 1.00% | Test loss: 0.0150, Test Acc: 1.00%
Epoch: 500 | Loss: 0.0170, Acc: 1.00% | Test loss: 0.0143, Test Acc: 1.00%
Epoch: 510 | Loss: 0.0163, Acc: 1.00% | Test loss: 0.0137, Test Acc: 1.00%
Epoch: 520 | Loss: 0.0157, Acc: 1.00% | Test loss: 0.0131, Test Acc: 1.00%
Epoch: 530 | Loss: 0.0151, Acc: 1.00% | Test loss: 0.0126, Test Acc: 1.00%
Epoch: 540 | Loss: 0.0145, Acc: 1.00% | Test loss: 0.0121, Test Acc: 1.00%
Epoch: 550 | Loss: 0.0140, Acc: 1.00% | Test loss: 0.0116, Test Acc: 1.00%
Epoch: 560 | Loss: 0.0135, Acc: 1.00% | Test loss: 0.0112, Test Acc: 1.00%
Epoch: 570 | Loss: 0.0130, Acc: 1.00% | Test loss: 0.0108, Test Acc: 1.00%
Epoch: 580 | Loss: 0.0126, Acc: 1.00% | Test loss: 0.0104, Test Acc: 1.00%
Epoch: 590 | Loss: 0.0122, Acc: 1.00% | Test loss: 0.0101, Test Acc: 1.00%
Epoch: 600 | Loss: 0.0118, Acc: 1.00% | Test loss: 0.0097, Test Acc: 1.00%
Epoch: 610 | Loss: 0.0114, Acc: 1.00% | Test loss: 0.0094, Test Acc: 1.00%
Epoch: 620 | Loss: 0.0111, Acc: 1.00% | Test loss: 0.0091, Test Acc: 1.00%
Epoch: 630 | Loss: 0.0108, Acc: 1.00% | Test loss: 0.0089, Test Acc: 1.00%
Epoch: 640 | Loss: 0.0104, Acc: 1.00% | Test loss: 0.0086, Test Acc: 1.00%
Epoch: 650 | Loss: 0.0102, Acc: 1.00% | Test loss: 0.0083, Test Acc: 1.00%
Epoch: 660 | Loss: 0.0099, Acc: 1.00% | Test loss: 0.0081, Test Acc: 1.00%
Epoch: 670 | Loss: 0.0096, Acc: 1.00% | Test loss: 0.0079, Test Acc: 1.00%
Epoch: 680 | Loss: 0.0094, Acc: 1.00% | Test loss: 0.0077, Test Acc: 1.00%
Epoch: 690 | Loss: 0.0091, Acc: 1.00% | Test loss: 0.0075, Test Acc: 1.00%
Epoch: 700 | Loss: 0.0089, Acc: 1.00% | Test loss: 0.0073, Test Acc: 1.00%
Epoch: 710 | Loss: 0.0087, Acc: 1.00% | Test loss: 0.0071, Test Acc: 1.00%
Epoch: 720 | Loss: 0.0085, Acc: 1.00% | Test loss: 0.0069, Test Acc: 1.00%
Epoch: 730 | Loss: 0.0083, Acc: 1.00% | Test loss: 0.0067, Test Acc: 1.00%
Epoch: 740 | Loss: 0.0081, Acc: 1.00% | Test loss: 0.0066, Test Acc: 1.00%
Epoch: 750 | Loss: 0.0079, Acc: 1.00% | Test loss: 0.0064, Test Acc: 1.00%
Epoch: 760 | Loss: 0.0077, Acc: 1.00% | Test loss: 0.0063, Test Acc: 1.00%
Epoch: 770 | Loss: 0.0076, Acc: 1.00% | Test loss: 0.0061, Test Acc: 1.00%
Epoch: 780 | Loss: 0.0074, Acc: 1.00% | Test loss: 0.0060, Test Acc: 1.00%
Epoch: 790 | Loss: 0.0073, Acc: 1.00% | Test loss: 0.0058, Test Acc: 1.00%
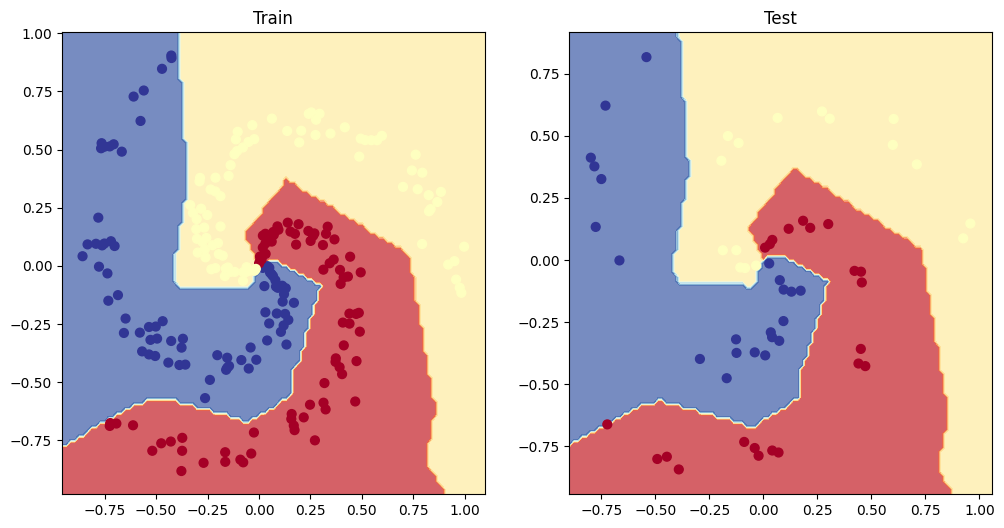
5. Make predictions with your trained model and plot them using the plot_decision_boundary() function created in this notebook.
# Plot the model predictions
import numpy as np
def plot_decision_boundary(model, X, y):
# Put everything to CPU (works better with NumPy + Matplotlib)
model.to("cpu")
X, y = X.to("cpu"), y.to("cpu")
# Source - https://madewithml.com/courses/foundations/neural-networks/
# (with modifications)
x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 101),
np.linspace(y_min, y_max, 101))
# Make features
X_to_pred_on = torch.from_numpy(np.column_stack((xx.ravel(), yy.ravel()))).float()
# Make predictions
model.eval()
with torch.inference_mode():
y_logits = model(X_to_pred_on)
# Test for multi-class or binary and adjust logits to prediction labels
if len(torch.unique(y)) > 2:
y_pred = torch.softmax(y_logits, dim=1).argmax(dim=1) # mutli-class
else:
y_pred = torch.round(torch.sigmoid(y_logits)) # binary
# Reshape preds and plot
y_pred = y_pred.reshape(xx.shape).detach().numpy()
plt.contourf(xx, yy, y_pred, cmap=plt.cm.RdYlBu, alpha=0.7)
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
# Plot decision boundaries for training and test sets
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_1, X_train, y_train)
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_1, X_test, y_test)
6. Replicate the Tanh (hyperbolic tangent) activation function in pure PyTorch.
- Feel free to reference the ML cheatsheet website for the formula.
# Create a straight line tensor
A = torch.arange(-10, 10, 1, dtype=torch.float)
plt.plot(A);
# Test torch.tanh() on the tensor and plot it
plt.plot(torch.tanh(A));
# Replicate torch.tanh() and plot it
def tanh(x: torch.Tensor) -> torch.Tensor:
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x))
plt.plot(tanh(A))
[<matplotlib.lines.Line2D at 0x7c0268358a30>]
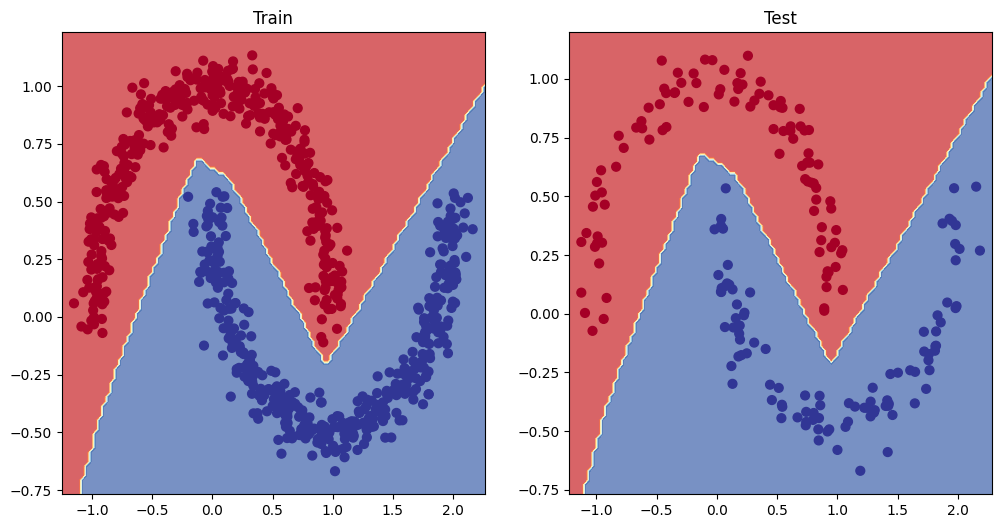
7. Create a multi-class dataset using the spirals data creation function from CS231n (see below for the code).
- Split the data into training and test sets (80% train, 20% test) as well as turn it into PyTorch tensors.
- Construct a model capable of fitting the data (you may need a combination of linear and non-linear layers).
- Build a loss function and optimizer capable of handling multi-class data (optional extension: use the Adam optimizer instead of SGD, you may have to experiment with different values of the learning rate to get it working).
- Make a training and testing loop for the multi-class data and train a model on it to reach over 95% testing accuracy (you can use any accuracy measuring function here that you like) - 1000 epochs should be plenty.
- Plot the decision boundaries on the spirals dataset from your model predictions, the
plot_decision_boundary()function should work for this dataset too.
# Code for creating a spiral dataset from CS231n
import numpy as np
import matplotlib.pyplot as plt
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
N = 100 # number of points per class
D = 2 # dimensionality
K = 3 # number of classes
X = np.zeros((N*K,D)) # data matrix (each row = single example)
y = np.zeros(N*K, dtype='uint8') # class labels
for j in range(K):
ix = range(N*j,N*(j+1))
r = np.linspace(0.0,1,N) # radius
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
# lets visualize the data
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)
plt.show()
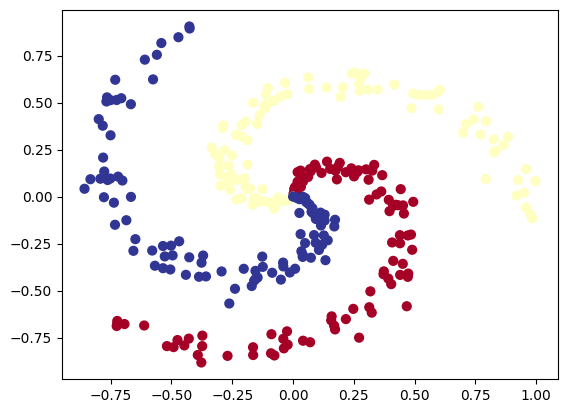
# Turn data into tensors
import torch
X = torch.from_numpy(X).type(torch.float) # features as float32
y = torch.from_numpy(y).type(torch.LongTensor) # labels need to be of type long
# Create train and test splits
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,
y,
train_size=0.8,
random_state=RANDOM_SEED)
# Let's calculuate the accuracy for when we fit our model
!pip -q install torchmetrics # colab doesn't come with torchmetrics
from torchmetrics import Accuracy
acc_fn = Accuracy(task="multiclass", num_classes=3).to(device)
acc_fn
MulticlassAccuracy()
import torch
from torch import nn
# Prepare device agnostic code
device = "cuda" if torch.cuda.is_available() else "cpu"
# Create model by subclassing nn.Module
class SpiralModelV0(nn.Module):
def __init__(self, input_features, output_features, hidden_layers=8):
super().__init__()
self.layer_stack = nn.Sequential(
nn.Linear(in_features=input_features, out_features=hidden_layers),
nn.ReLU(),
nn.Linear(in_features=hidden_layers, out_features=hidden_layers),
nn.ReLU(),
nn.Linear(in_features=hidden_layers, out_features=output_features)
)
def forward(self, x):
return self.layer_stack(x)
# Instantiate model and send it to device
model_2 = SpiralModelV0(input_features=2,
output_features=4).to(device)
model_2
SpiralModelV0(
(layer_stack): Sequential(
(0): Linear(in_features=2, out_features=8, bias=True)
(1): ReLU()
(2): Linear(in_features=8, out_features=8, bias=True)
(3): ReLU()
(4): Linear(in_features=8, out_features=4, bias=True)
)
)
# Setup data to be device agnostic
X_train, y_train = X_train.to(device), y_train.to(device)
X_test, y_test = X_test.to(device), y_test.to(device)
# Print out first 10 untrained model outputs (forward pass)
print("Logits:")
print(model_2(X_train)[:10])
print("Pred probs:")
print(torch.softmax(model_2(X_train), dim=1)[:10])
print("Pred labels:")
print(torch.argmax(torch.softmax(model_2(X_train), dim=1), dim=1)[:10])
Logits:
tensor([[ 0.0791, 0.0745, 0.2463, -0.2812],
[ 0.0864, 0.1098, 0.2242, -0.3137],
[ 0.0868, 0.0557, 0.2577, -0.2360],
[ 0.1355, 0.1314, 0.1801, -0.2783],
[ 0.1322, 0.0594, 0.2133, -0.2206],
[ 0.0855, 0.0591, 0.2547, -0.2412],
[ 0.0870, 0.0551, 0.2582, -0.2352],
[ 0.0834, 0.0516, 0.2619, -0.2518],
[ 0.0939, 0.1061, 0.2272, -0.2957],
[ 0.1372, 0.1326, 0.1782, -0.2782]], device='cuda:0',
grad_fn=<SliceBackward0>)
Pred probs:
tensor([[0.2581, 0.2569, 0.3050, 0.1800],
[0.2603, 0.2665, 0.2988, 0.1745],
[0.2577, 0.2499, 0.3058, 0.1866],
[0.2701, 0.2690, 0.2824, 0.1785],
[0.2690, 0.2502, 0.2918, 0.1891],
[0.2578, 0.2510, 0.3053, 0.1859],
[0.2577, 0.2496, 0.3059, 0.1867],
[0.2578, 0.2497, 0.3081, 0.1844],
[0.2609, 0.2642, 0.2982, 0.1767],
[0.2705, 0.2692, 0.2818, 0.1785]], device='cuda:0',
grad_fn=<SliceBackward0>)
Pred labels:
tensor([2, 2, 2, 2, 2, 2, 2, 2, 2, 2], device='cuda:0')
# Setup loss function and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params=model_2.parameters(),
lr=0.2)
# Build a training loop for the model
epochs = 200
# Loop over data
for epoch in range(epochs):
## Training
model_2.train()
# 1. Forward pass
y_logits = model_2(X_train).squeeze()
y_pred_probs = torch.softmax(y_logits, dim=1)
y_pred = torch.argmax(torch.softmax(y_logits, dim=1), dim=1)
# 2. Calculate the loss
loss = loss_fn(y_logits, y_train)
acc = acc_fn(y_pred, y_train)
# 3. Optimizer zero grad
optimizer.zero_grad()
# 4. Loss backward
loss.backward()
# 5. Optimizer step
optimizer.step()
## Testing
model_2.eval()
with torch.inference_mode():
# 1. Forward pass
test_logits = model_2(X_test).squeeze()
test_pred_probs = torch.softmax(test_logits, dim=1)
test_pred = torch.argmax(torch.softmax(test_logits, dim=1), dim=1)
# 2. Caculate loss and acc
test_loss = loss_fn(test_logits, y_test)
test_acc = acc_fn(test_pred, y_test)
# Print out what's happening every 100 epochs
if epoch % 100 == 0:
print(f"Epoch: {epoch} | Loss: {loss:.4f}, Acc: {acc:.2f}% | Test loss: {test_loss:.4f}, Test Acc: {test_acc:.2f}%")
Epoch: 0 | Loss: 1.3099, Acc: 0.32% | Test loss: 1.2009, Test Acc: 0.37%
Epoch: 100 | Loss: 0.0488, Acc: 0.98% | Test loss: 0.0166, Test Acc: 1.00%
# Plot decision boundaries for training and test sets
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_2, X_train, y_train)
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_2, X_test, y_test)